
|
Esta ciencia, cuenta con una unidad de análisis, que son aquellos objetos de los cuales se desea obtener información.
o La población o universo es el conjunto de unidades de análisis. En general, este conjunto, comparte alguna o varias características en común. La población de individuos son todos los individuos que comparten cierta característica; la población de observaciones son todos los valores de variables que puede tomar una observación.
o La MUESTRA es una parte o un subconjunto de unidad de análisis de una población dada. Es así, que la muestra de individuos es un grupo o subconjunto de la población de individuos.
ESTADÍSTICA DESCRIPTIVA
Es un conjunto de técnicas para resumir y trasmitir información cuantitativa. Sirve para analizar las características de una población y a descubrir las regularidades existentes dentro de un conjunto de datos .
Una variable es una propiedad o cualidad de los individuos de una población. Las modalidades son cada una de las formas en las que se presenta una característica. Las variables presentan distintas modalidades (dos o más) entre los individuos. Si presenta una única modalidad es una constante.
Operacionalizacion= Proceso de medición = Valor a la variable = Variable estadísitica
La operacionalización de un constructo es lo que permite asignar sin ambigüedad un valor a la variable a través de un proceso de medición. En la operacionalización de una variable se indica detalladamente los procedimientos a usar para obtener el valor de la variable que corresponde a cada individuo.
Al operacionalizar una variable, se obtiene una variable estadística que es una representación, a través de números u otros símbolos, de una variable. Se obtiene mediante algún procedimiento de medición.
CLASIFICACIONES DE VARIABLES:
§ Cualitativas: Sus valores designan atributos. EJ: Soltero o Casado. Indican si los valores son iguales o diferentes en la característica de interés.
§ Cuasicuantitativa: A partir de esta variable se puede establecer un orden de valores o jerarquía. EJ: Nivel de ansiedad: Bajo, Medio, Alto.
§ Cuantitativas: Expresan cantidades numéricas. Indica cantidad.
§ Cuantitativas discretas: Sus valores son puntos aislados y todo valor tiene un consecutivo. No puede existir un valor entre ellos. Son números enteros. EJ: Cantidad de intentos de suicidio de un paciente (Puede haber sido 1, 2 o 3; pero no 1,5)
§ Cuantitativas continuas: Puede tomar cualquier calor dentro de un intervalo numérico al menos teóricamente. Pueden ser números decimales. EJ: Tiempo invertido en realizar un test de inteligencia (Puede ser una hora, treina minutos y sesenta y dos segundos)
Niveles de medición---------------------------------------------------------------
Homorfismo: Es necesario que la relación de valores se respete siempre.
§ NIVEL NOMINAL: Designa atributos. La relación entre los valores es de igualdad o diferencia. Ej.: Diagnóstico clínico.
§ NIVEL ORDINAL: Establece un orden o jerarquía entre los valores. Permite saber que algo es mayor o menor a otra cosa. Ej: Escala de grado de satisfacción.
§ NIVEL INTERVALAR: Incluye unidad de medida. Incluye la posibilidad de determinar la distancia entre dos valores. El cero no indica la ausencia de la característica, es arbitrario. Por ejemplo: puntajes de test psicológico.
§ NIVEL DE RAZÓN O COCIENTE: Incluye unidad de medida. Permite establecer proposiciones. El cero es absoluto e indica la ausencia de la característica.
ESTADÍSTICA INFERENCIAL
Sirve para hacer inferencias, generalizaciones y extrapolaciones de un conjunto de datos a un conjunto mayor.
_________________________ Otros conceptos ________________________
§ El parámetro poblacional es una propiedad descriptiva de una población. Generalmente el parámetro es desconocido y el principal interés del investigador es conocer su valor.
§

El estadístico es una propiedad descriptiva de una muestra. Su valor en general se puede calcular a
partir de la información que la muestra provee.
§ El estimador es un estadístico que se utiliza para conocer aproximadamente el valor de un parámetro desconocido.
ORGANIZACIÓN DE DATOS Y DISTRIBUCION DE FRECUENCIAS
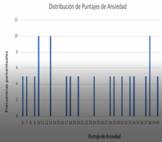
Las distribuciones de frecuencias son agrupaciones de los datos en tablas o gráficos, para organizarlos de formas resumidas y ordenadas. Las frecuencias absolutas, expresan la cantidad de veces que se repite una determinada modalidad. A partir de esta, se puede calcular la frecuencia relativa, que es la frecuencia absoluta dividida por el total de los datos, y la frecuencia porcentual, que es la frecuencia relativa multiplicada por 100. Estas dos ultimas frecuencias, informan acerca del peso de cada valor de la variable en el conjunto de observaciones.
La frecuencia absoluta acumulada es la cantidad de observaciones acumuladas hasta determinada modalidad de la variable, y se usa para determinar cuántas observaciones son menores o iguales a cierto valor.
Los gráficos se utilizan para interpretar fácilmente los datos de las distribuciones de frecuencias.
|
GRÁFICOS |
||
|
VARIABLE CUALITATIVA |
NOMINAL |
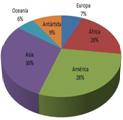
o Diagrama circular
o Gráfico de barras
|
|
ORDINAL |
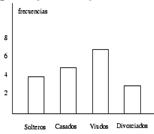
o Gráfico de barras
|
|
|
VARIABLE CUALITATIVA |
DISCRETA |
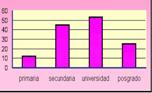
o Gráfico de barras o Gráfico de bastones
o Polígono de frecuencias
|
|
DE RAZÓN |
||
|UNIDAD 3: RESUMENES ESTADÍSTICOS|
Los resúmenes estadísticos dan una idea del comportamiento de los datos en una muestra, resumiendo la información contenida en las observaciones.
u Medidas de posición:
Sirven para entender cómo se sitúa una puntuación con respecto a su grupo de referencia, indicando qué porcentajes de la muestra quedan por debajo de un valor determinado de la variable. Centiles, Cuartiles (3 valores que dividen en 4 partes a la distribución). El valor k, que es un rango percentilar que indica cual es el porcentaje de las observaciones que es superado por un valor de la variable.
u Medidas de tendencia central
Resumen en un solo valor de la variable, la tendencia general que se observa en la distribución. La moda es el valor que más se repite en la distribución. La mediana es el valor central de la distribución. La media es el promedio de los valores de la distribución, que se obtiene sumando cada una de las puntuaciones y dividiéndolas por el total de observaciones.
u Medidas de variación:
Indican el grado de dispersión que se presenta en la distribución de frecuencias. Cuando mayor es la distancia entre la puntuación y su media, mayor es la dispersión de ese valor. Cuando la distancia es menor, quiere decir que la variación es menor, y que cierta puntuación es mas representativa con respecto a los valores de la muestra.
El rango es una de las formas mas sencillas de calcular la variación de una muestra; consiste en sacar la diferencia del valor mayor de la distribución y del menor. Sin embargo, esta medida solo contempla los valores extremos, volviéndose menos representativa con respecto a la dispersión del total de la muestra.
La varianza es otro índice de variabilidad. Sirve para comparar el grado de dispersión de dos o mas conjuntos de valores en una misma variable. Se obtiene elevando al cuadrado las distancias de una puntuación respecto de su media, y dividiéndolas por n, es decir, por el total de las observaciones.
El desvío típico es un índice que deriva de la varianza. Es una forma más sencilla de interpretar los datos. Se calcula sacando la raíz cuadrada de la varianza.
u Medidas de variación relativas:
Cuando se presentan dos grupos de datos con medias muy diferentes, es posible utilizar el índice de coeficiente de variación, que es una medida de variabilidad relativa. Se calcula dividiendo el desvió típico por la media y multiplicando la división por 100.
u Las medidas de asimetría y curtosis son otra forma de describir y comparar distribuciones de frecuencias. Estas ayudan a entender las diferencias entre los grupos. El grado de asimetría hace referencia al grado en que los datos se reparten equilibradamente por encima o por debajo de la tendencia central. Los datos pueden presentar asimetría negativa, que implica que haya mayor cantidad de datos por encima de la media; asimetría positiva, donde hay mayor concentración de datos inferiores a la media, o pueden comportarse de forma simétrica, donde la moda y la media estarán en el mismo punto.
Por otro lado, el índice de curtosis puede ser leptocúrtico, platicurtico y mesocúrtico.
|UNIDAD 4|
Las puntuaciones directas Xi (observadas o brutas) resultan insuficientes para interpretar los datos observados ya que no nos permite saber acerca de la tendencia central del conjunto de datos del cual proviene esa puntuación directa, ni la variabilidad de tal conjunto de datos. Una primera forma para poder interpretar cómo se ubica esa puntuación en relación con su grupo de referencia , es a través de las puntuaciones diferenciales: Se obtienen restando Xi por su media. Las puntuaciones diferenciales indican si la puntuación es superior, inferior o igual a la media. Sin embargo, no brinda información acerca de la variabilidad del conjunto de datos al que pertenece la puntuación directa Xi.
Las puntuaciones típicas (Zi) y lasescalas derivadas (Ti) se basan en aplicar transformaciones de las puntuaciones directas, produciendo otras que, sin perder o distorsionar la información contenida en las puntuaciones originales, permiten una interpretación y una comparación más eficiente de las mismas.
Zi permite ubicar la posición de un individuo en relación con su grupo de referencia.
Características de la puntuación típica
Ø Se obtienen dividiendo la puntuación diferencial (puntuación directa menos la media) por la desviación típica.
Ø Permite medir las distancias a la media con relación a la variabilidad del grupo de referencia.
Ø Tend. central y variabilidades universales; Media=0 Varianza y Desvío típico= 1
Ø Son adimensionales (independientes de la unidad de medida) por lo que permiten realizar comparaciones, llevando los resultados a una escala común.
Ø Son útiles para realizar comparaciones entre unidades de distintos grupos (poblaciones o muestras); entre variables medidas de distintas formas; entre variables distintas.
Algunas de las puntuaciones típicas son negativas y casi todas tienen decimales. Por esa razón, se han buscado otras puntuaciones que permitan resolver estas dificultades:
Las escalas derivadas (Ti) constituyen una transformación de las Zi en otras equivalentes. A la puntuación típica se la multiplica por una desviación típica constante y se le suma una media constante.
Hay algunas escalas derivadas de uso habitual como las puntuaciones T que tiene una media de 50 y una desviación típica de 10; o las escalas de cociente intelectual (CI) que tiene una media de 100 y un desvío típico de 15.
|UNIDAD 5|
El coeficiente de relación de Pearson es un índice que mide la relación lineal, es decir, que mide la asociación entre dos variables cuantitativas. Puede valer entre -1 y 1, y no tiene una unidad de medida. El r informa acerca de si las variables se asocian linealmente, pero dicha asociación no supone causalidad.
En la interpretación de una correlación hay que separar la cuantía y el sentido.
La cuantía se refiere al grado en que la asociación entre dos variables queda bien descripta con un índice de asociación lineal como r. Un valor de +- 1 indica un grado perfecto de asociación entre las dos variables. En la medida en que el coeficiente de correlación de acerca a 0, la relación entre las dos variables será mas débil.
El sentido refiere al tipo de relaciones: directa o inversa. La dirección de la relación es indicada por el signo del coeficiente, un signo + indica una relación directa o positiva, y un signo – indica una relación inversa o negativa entre las dos variables.
Los GRÁFICOS ASOCIADOS AL COEFICIENTE DE RELACIÓN R DE PEARSON SE DENOMINAN DIAGRAMAS DE DISPERSIÓN O DISPERSOGRAMAS, y la configuración de puntos resultante se denomina nube de puntos.
RELACIÓN LINEAL DIRECTA O POSITIVA :
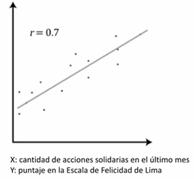 Los puntos en el diagrama tienden a ubicarse en torno a una recta
creciente, y las variables covarían en el mismo sentido.
Es decir, cuando a valores bajos de una de ella, le corresponden valores
bajos de la otra, y así con los valores medios y altos.
Los puntos en el diagrama tienden a ubicarse en torno a una recta
creciente, y las variables covarían en el mismo sentido.
Es decir, cuando a valores bajos de una de ella, le corresponden valores
bajos de la otra, y así con los valores medios y altos.
Se encuentran cada vez más cercanos al R=1
RELACIÓN LINEAL INVERSA O NEGATIVA:
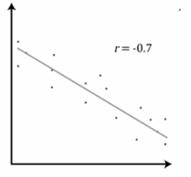
Se detecta esta entre dos variables cuando covarían en sentido contrario, es decir, cuando a valores bajos de una de ellas corresponden valores altos de la otra
RELACIÓN NULA:
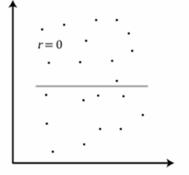
Los puntos están distribuidos en el plano sin ninguna estructura particular, lo cual demuestra que estas dos variables no están relacionadas y son independientes.
Se acercan o igualan a un R=0
La relación lineal nula puede deberse a dos casos:
1) Las dos variables son independientes. De manera que no están asociadas linealmente
2) Las dos variables estén relacionadas, pero de manera no lineal. De manera que el r de Pearson no capta esa relación.
|Unidad 6|
Modelos teóricos: son una construcción teórica. A partir de una representación simplificada de la realidad permiten una mejor comprensión de esta, facilitando su análisis e interpretación y la formulación de conclusiones y predicciones. Al confrontarse con la realidad observada, el investigador pone a prueba el modelo teórico propuesto, para ver si explica y predice lo que sucede en la realidad.
Un modelo para una variable es una distribución de frecuencias relativas teóricas. Estas frecuencias relativas, no se fundamentan en la observación directa, sino que son postuladas. La experiencia previa justifica los valores propuestos, o es deducida a partir de ciertas condiciones teóricas. Las F. R. T. se denominan probabilidades.
La probabilidad de un valor de la variable es la proporción de casos que se espera que ese valor de la variable tenga en una población. Es una medida de la posibilidad de que dicho valor sea observado.
u Variables dicotómicas: Variables cualitativas que toman dos valores.
Cuando uno habla de un modelo de distribución se refiere a una forma que adquieren los datos, dependiendo de la variabilidad que presentan. Dependiendo de esa forma, se pueden derivar probabilidades teóricas de ocurrencias de un evento.
MODELO DE DISTRIBUCIÓN BINOMIAL:
Una distribución binomial es una distribución de probabilidadcuantitativa discreta que describe el número de éxitos que se pueden observar en una serie de pruebas o ensayos, donde la variable es dicotómica (es decir que solo se pueden obtener 2 resultados: éxitos o fracasos) y aleatoria, es decir que son al azar, ya que dependen de eventos cuyos resultados no se pueden predecir con cereza.
Condiciones necesarias para la aplicación del modelo Binomial
u Estabilidad: la probabilidad de éxito debe permanecer constante en las n observaciones de la variable dicotómica.
u Independencia: la probabilidad de obtener éxito en una observación no aumenta ni disminuye si se conoce el resultado de otra observación.
MODELO DE DISTRIBUCIÓN NORMAL:
Es uno de los modelos de distribución más utilizado, que sirve para variables cuantitativas discretas. Sus parámetros son la media poblacional (mu) y el desvío poblacional (sigma). Dentro de la psicología hay multiples variables que se ajustan a este modelo, como el tiempo de reacción o las medidas de aptitudes.
Los valores en este modelo se distribuyen formando una campana de Gauss, en torno a un valor central que coincide con los valores de las medidas de tendencia central. La mayor cantidad de las observaciones se ubican en valores medios, y la menor cantidad se encuentran por abajo o por encima de los valores de las medidas de tendencia central. Por eso, a medida que nos alejamos del centro, la probabilidad asociada a observar ese valor va disminuyendo.
Propiedades:
u Es una distribución simétrica, en donde coinciden las 3 MTC.
u Es asintótica.
u Dentro de la familia de curvas normales, la más importante se denomina distribución normal unitaria y tiene una media 0 y desviación típica 1
u Los puntos de inflexión se encuentran en los puntos correspondientes a la media más/menos una desviación típica.
DISTRIBUCIÓN DE LA MEDIA MUESTRAL
La media muestral es una variable, por lo que tiene su propia distribución de probabilidad. Si somos capaces de saber cuál es esa distribución, entonces podremos calcular las probabilidades asociadas a los posibles valores de ese estadístico.
Distribución de la media muestral:
● Es una distribución teórica que asigna una probabilidad concreta a cada uno de los valores que puede tomar la media muestral en todas las muestras del mismo tamaño que es posible extraer de una determinada población.
● El centro de la distribución muestral de x̄ es el mismo que el de la distribución poblacional de la variable X → μ = μX
● La variabilidad de la distribución muestral de x̄ es menor a la de la variable X: Cuanto más grande sea el n de la muestra, más se parecerá la media muestral a la poblacional, y por lo tanto la variabilidad o dispersión de las con respecto a la media poblacional será menor, y las medias muestrales variarán menos.
● La varianza de la distribución muestral de x̄ es igual a la varianza poblacional de X dividida por el tamaño de la muestra
● Como la desviación típica es la raíz cuadrada de la varianza, la desviación típica de la distribución de es igual a la desviación típica poblacional de X dividida por la raíz cuadrada del tamaño de la muestra → σ = σX / √n
CONTRASTE DE HIPÓTESIS
Es el instrumento estadístico inferencial que permite evaluar a partir de los datos de una muestra representativa, la veracidad de afirmaciones hechas sobre una población. Puede ser entendido como un método de toma de decisiones.
No todas las muestras sirven para hacer inferencias, ya que es necesario que sean representativas de la población.
La HIPÓTESIS CIENTÍFICA es una afirmación referida a una o varias características de una población. No es directamente evaluable a partir de los datos muestrales, sino que es necesario transformar esta hipótesis en una hipótesis estadística. La H IPÓTESIS ESTADÍSTICA es la transformación de una hipótesis científica para que pueda ser verificable utilizando métodos estadísticos; tiene que ser completamente equivalente a la original, pero representada para que sea factible analizar los datos muestrales mediante un método de inferencia estadística y poder determinar su veracidad.
La teoría de contraste de hipótesis hace referencia a dos hipótesis: Lahipótesis nula (H0) y la hipótesis alternativa.
● Hipótesis nula (H0): Es la hipótesis que se somete a contraste. Es la única que se puede rechazar o no rechazar, mantener o corroborar.
● Hipótesis alternativa (H1): Es complementaria con la anterior, en general es la hipótesis de investigación, la que se quiere comprobar, y así tomar una decisión. Es inexacta, incluye todo lo que la nula (H0) excluye. A diferencia de la nula, tiene otras opciones (< (unilateral izquierda), >(unilateral derecho), ≠ (contraste bilateral)), está relacionada con la pregunta del investigador.
Quien investiga decide sobre la veracidad de una hipótesis o afirmación a nivel de población, a partir de la información que provee una muestra. Al hacer esto, es posible que la decisión tomada pueda ser errónea:
• Error de tipo 1: rechazar H0 cuando es verdadera
• Error de tipo 2: aceptar H0 cuando es falsa
Regla de decisión → los contrastes de hipótesis tienen un esquema que permite determinar si H0 debe ser rechazada o no. Esta regla de decisión depende del estadístico de prueba de su distribución (indicador numérico que puede ser calculado a partir de la información de la muestra, que tiene distribución de probabilidad conocida), del tipo de hipótesis alternativa que se está considerando, y también depende del nivel de significación o probabilidad de error de tipo 1 que se haya fijado.
Puede fijarse de dos formas:
● Regla de decisión basada en la zona de rechazo: Consiste en la comparación del estadístico con la ZR, entonces:
○ Si el valor del estadístico pertenece a la ZR: se rechaza H0.
○ Si el valor del estadístico no pertenece a la ZR: no se rechaza H0.
La ZR es el conjunto de valores del estadístico de prueba que hacen que se decida rechazar H0. Así como existe una ZR, existe una zona de aceptación, que se define como el conjunto de valores del estadístico que hacen que se decida no rechazar H0.
● Regla de decisión basada en el valor P: Consiste en la comparación de esta probabilidad con el nivel de α que el investigador haya fijado a priori, entonces:
○ Si el valor de P es menor que α: se rechaza H0.
○ Si el valor de P es mayor que α: no se rechaza H0.
Valor P→ probabilidad de éxito en cada uno de los ensayos de la variable dicotómica